Topics
Logical topics
Logical topics are abstractions over real Kafka topics to provide additional functionalities not possible by default. Conduktor offers three types of logical topics:
-
Alias topics are topics that can be accessed with a name, but really points to another real topic behind the scenes. It can be useful in a few scenarios such a topic renaming or cross virtual cluster topic sharing.
-
Concentrated topics allow co-locating multiple topics in the same physical topic behind the scenes. It's very useful when you want to regroup many topics with low-volume but a large number of partitions.
-
SQL topics are using SQL language to query & filter an existing topic, very useful to filter out the records that doesn't correspond to your business needs.
Alias topics
Alias topics are logical topics that target a different physical topic. They act like pointers to another physical topic.
Purpose
One of Kafka's limitations is that you cannot rename topics.
Use
Gateway manages an alias topic mapping in it's internal configuration by registering a target physical topic. This topic will be presented to Kafka clients like a regular topic. However, all requests for this topic will be forwarded to the physical topic.
This means that consumer groups, fetch and produce are shared. Also, the alias topic will not replace the original one.
For example, if you create an alias topic, applicationB_orders pointing to a physical topic orders, a client that's able to access the physical one would be able to see both topics.
Limitations
- ACLs using delegated Kafka security SASL delegated security protocols aren't supported.
- Alias topics can't reference another alias topic.
Concentrated topics
Concentrated topics transparently act as pointers to a single physical topic on your Kafka cluster. They allow you to reduce costs on low-volume topics by co-locating messages.
They are completely transparent to consumers and producers and allow you to emulate different partition counts irrespective of the backing physical topic's partition count.
Use
To create concentrated topics, first deploy a ConcentrationRule:
---
kind: ConcentrationRule
metadata:
name: concentration1
spec:
pattern: concentrated.*
physicalTopics:
delete: physical.topic
Then topics that match the ConcentrationRule spec.pattern:
kafka-topics \
--bootstrap-server conduktor-gateway:6969 \
--topic concentrated.topicA \
--partitions 3
kafka-topics \
--bootstrap-server conduktor-gateway:6969 \
--topic concentrated.topicB \
--partitions 4
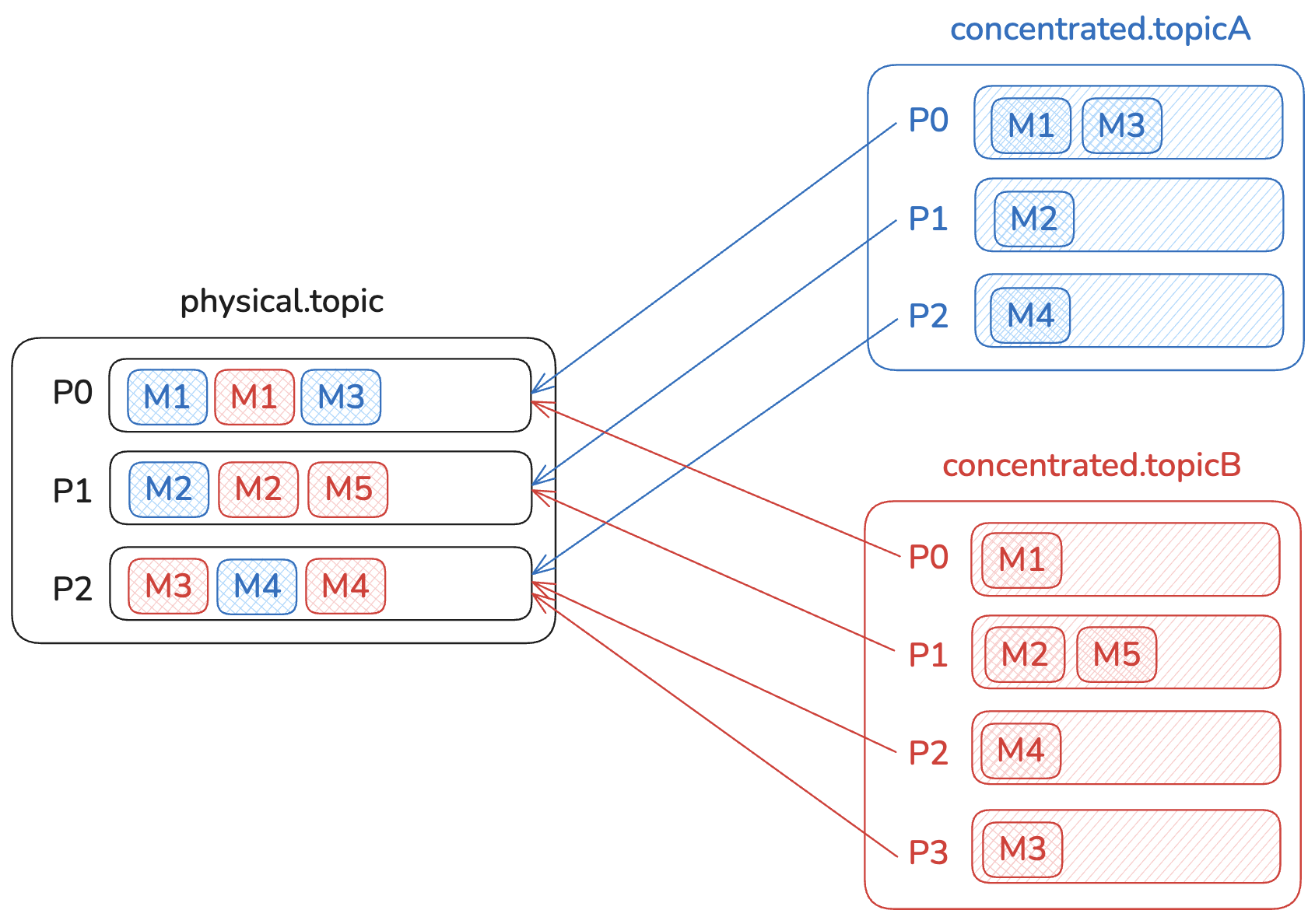
We now have two concentrated topics (concentrated.topicA & concentrated.topicB) with partition counts of 3 and 4 respectively, mapped to a single physical topic (physical.topic) with three partitions.
To ensure that consumers don't consume messages from other partitions or from other concentrated topics, we store the concentrated partition and the concentrated topic name in the record headers. Gateway will automatically filter the messages that should be returned to the consumer.
Limitations
Compact and delete+compact topics
You can create concentrated topics with any cleanup.policy, but your ConcentrationRule has to have a backing topic for each of them, otherwise it won't let you create the topic.
---
kind: ConcentrationRule
metadata:
name: concentration1
spec:
pattern: concentrated.*
physicalTopics:
delete: physical.topic-delete
compact: physical.topic-compact
# deleteCompact: physical.topic-deletecompact
In this example, since the config for spec.deleteCompact is commented out, trying to create this topic will fail:
kafka-topics --create
--bootstrap-server conduktor-gateway:6969 \
--topic <your-topic-name> \
--partitions 3 \
--config cleanup.policy=compact,delete
Error while executing topic command : Cleanup Policy is invalid
Backing topic cleanup policies are checked when you deploy a new ConcentrationRule. This prevents you from declaring a backing topic with a cleanup.policy of delete on the ConcentrationRule spec.physicalTopic.compact field.
Restricted topic configurations
The following list of topic properties are the only allowed properties for concentrated topics:
partitionscleanup.policyretention.msretention.bytesdelete.retention.ms
If any other configuration than the above is set, the topic creation will fail with an error.
retention.ms and retention.bytes can be set to values lower or equal to the backing topic. If a user tries to create a topic with a higher value, topic creation will fail with an error:
kafka-topics --create
--bootstrap-server conduktor-gateway:6969 \
--topic <your-topic-name> \
--partitions 3 \
--config retention.ms=704800000
Error while executing topic command : Value '704800000' for configuration 'retention.ms' is incompatible with physical topic value '604800000'.
This behavior can be altered with the flag spec.autoManaged.
With concentrated topics, the enforced retention policy is the physical topic's retention policy, and not the policy requested at the concentrated topic creation time. The retention.ms and retention.bytes are not cleanup but retention guarantees.
Auto-managed backing topics
When autoManaged is enabled:
- backing topics are automatically created with the default cluster configuration and partition count.
- concentrated topics created with higher
retention.msandretention.bytesare allowed. It automatically extends the configuration of the backing topic.
---
kind: ConcentrationRule
metadata:
name: concentration1
spec:
pattern: concentrated.*
physicalTopics:
delete: physical.topic
autoManaged: true
Let's check the backing topic retention on the physical cluster:
kafka-configs --bootstrap-server kafka:9092 \
--entity-type topics --entity-name physical.topic \
--describe
Configs for topic 'physical.topic' are:
cleanup.policy=delete
retention.ms=604800000
retention.bytes=-1
Let's try to create a concentrated topic with a higher retention on Gateway:
kafka-topics --create
--bootstrap-server conduktor-gateway:6969 \
--topic <your-topic-name> \
--partitions 3 \
--config retention.ms=704800000
Let's review the backing topic again:
kafka-configs --bootstrap-server kafka:9092 \
--entity-type topics --entity-name physical.topic \
--describe
Configs for topic 'physical.topic' are:
cleanup.policy=delete
retention.ms=704800000
retention.bytes=-1
As we can see, the retention has been updated.
If one user requests a topic with infinite retention (retention.ms = -1), all the topics with the same cleanup policy associated with the rule will also inherit this extended configuration and have infinite retention.
Message count, lag and offset (in)correctness
By default, concentrated topic reports the offsets of their backing topics. This impacts the calculations of Lag and Message Count that relies on partition EndOffset and group CommitedOffset.
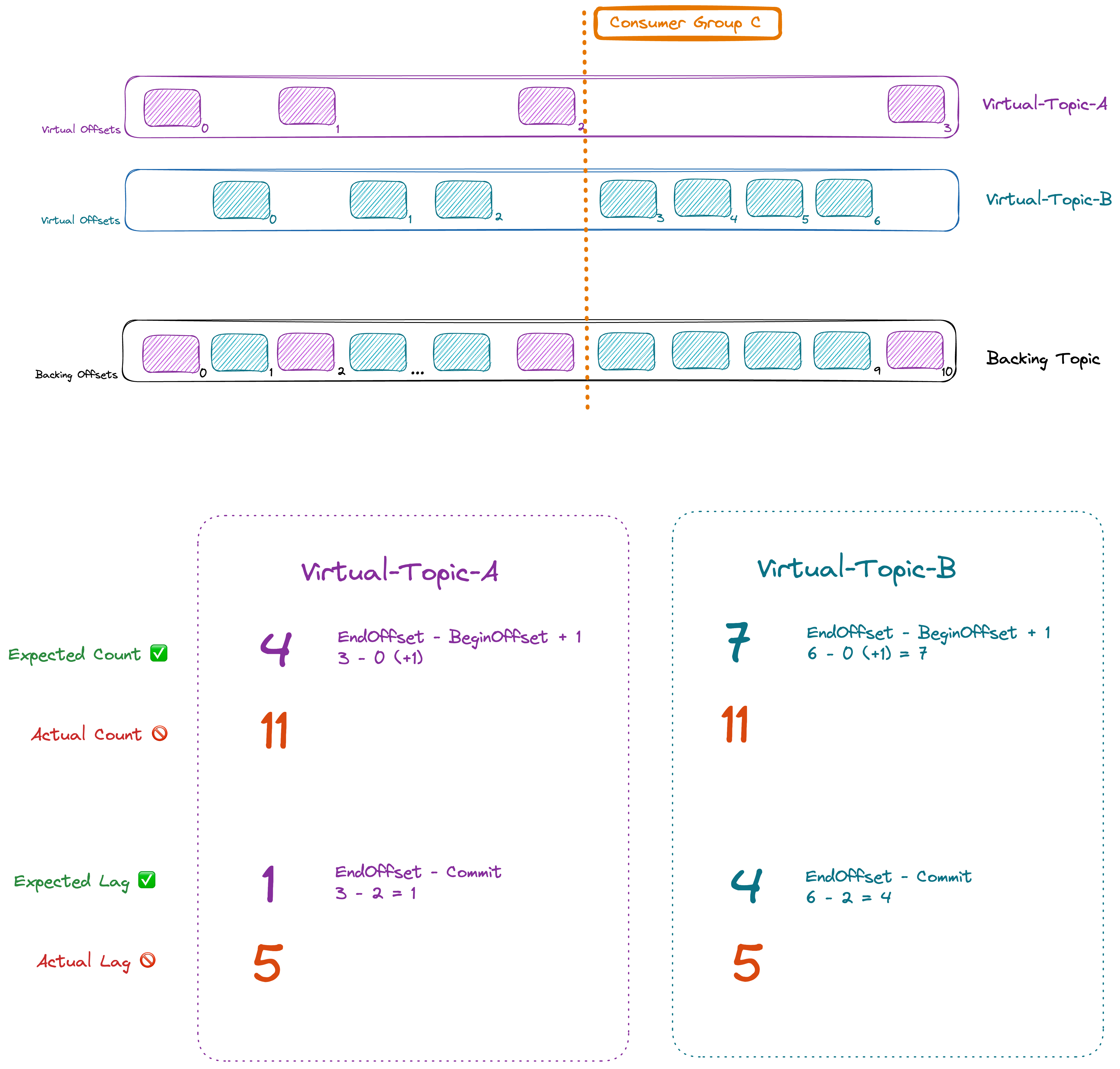
Any tooling will currently display the message count, and the lag relative to the EndOffset of the physical topic. This can create confusion for customers and applications that will see incorrect metrics.
To counter this, we've implemented a dedicated offset management capability for ConcentrationRules. To enable virtual offsets, add the following line to the ConcentrationRule:
---
kind: ConcentrationRule
metadata:
name: concentration1
spec:
pattern: concentrated.*
physicalTopics:
delete: physical.topic
offsetCorrectness: true
Note that:
spec.offsetCorrectnessonly applies to concentrated topics with thecleanup.policy=deletespec.offsetCorrectnessis not retroactive on previously created Concentrated Topics
Known issues and limitations with offset correctness
Performance
On startup, Gateway has to read the concentrated topic entirely before it's available to consumers. The end-to-end latency is increased by up to 500 ms (or fetch.max.wait.ms, if non-default).
Memory impact
Gateway consumes about ~250MB of heap memory per million records it's read in concentrated topics. This value is not bound, so we don't recommend offset correctness on high-volume topics, and recommend to size your JVM accordingly.
Unsupported Kafka API
DeleteRecordsis not supported- Transactions are not supported
- Only
IsolationLevel.READ_UNCOMMITTEDis supported (usingIsolationLevel.READ_COMMITTEDis undefined behavior) - Partition truncation (upon
unclean.leader.election=true) may not be detected by consumers
Very slow consumer group edge case
Do not enable offset correctness when your topic has extended periods of inactivity.
When using topic concentration with offsetCorrectness enabled, there's currently a limitation for consumer groups where the data in the topics is slow moving, and/or the consumer groups are not committing their offsets frequently.
If a consumer group with a committed offset waits for the backing physical topic longer than the retention time (without committing a new offset), there's a possibility for that consumer group to become blocked.
In this scenario, a consumer group whose last committed offset has been removed from the topic, the group becomes blocked only if Gateway restarted before the next offset commit. If this limitation happens, the offsets for the affected consumer group will need to be manually reset for it to continue.
SQL topics
Conduktor Gateway's SQL topic feature uses a SQL-like language to filter and project messages, based on a simple SQL statement:
SELECT
type,
price as amount,
color,
CASE
WHEN color = 'red' AND price > 1000 THEN 'Exceptional'
WHEN price > 8000 THEN 'Luxury'
ELSE 'Regular'
END as quality,
record.offset as record_offset,
record.partition as record_partition
FROM cars
This supports for FetchResponse only: (i.e., resulting topic is read-only).
SELECT [list of fields] FROM [topic name] WHERE [field filter criteria]
Note that topic names with dash - characters have to be double quoted, as the dash is not a valid character for a SQL name. For example: if you have a topic our-orders, use SELECT * FROM "our-orders" WHERE ...
Other limitations:
- With filter records based on more than one condition, only
ANDoperator is supported - Supported predicates:
=,>,>=,<,<=,<>andREGEXP(RegExp MySQL Operator) - Case expression is supported
- Filtered by:
- Record key (It supports SR):
- Record key as string: -
.. WHERE record.key = 'some thing' - Record key as schema:
.. WHERE record.key.someValue.someChildValue = 'some thing'
- Record key as string: -
- Record value (It supports SR):
.. WHERE $.someValue.someChildValue = 'some thing' - Partition:
.. WHERE record.partition = 1 - Timestamp:
.. WHERE record.timestamp = 98717823712 - Header:
.. WHERE record.header.someHeaderKey = 'some thing' - Offset:
.. WHERE record.offset = 1
- Record key (It supports SR):
Schemas and projections
If your data uses a schema, then it's not possible to make use of the projection feature here because the resulting data will no longer match the original schema. For plain JSON topics, you can use the SELECT clause to alter the shape of the data returned; however, for schema'd data (Avro and Protobuf) you must not use a projection, i.e. the select should be in the form:
SELECT * FROM ...
Filtering with the where clause is still supported.
Configuration
| Key | Type | Description |
|---|---|---|
| virtualTopic | String | if virtualTopic exists, fetch this topic will get the data from the statement without configure it's own statement. |
| statement | String | SQL Statement |
| schemaRegistryConfig | Schema Registry | Schema Registry Config |
Schema registry
| Key | Type | Default | Description |
|---|---|---|---|
type | string | CONFLUENT | The type of schema registry to use: choose CONFLUENT (for Confluent-like schema registries including OSS Kafka) or AWS for AWS Glue schema registries. |
additionalConfigs | map | Additional properties maps to specific security-related parameters. For enhanced security, you can hide the sensitive values using environment variables as secrets. | |
| Confluent Like | Configuration for Confluent-like schema registries | ||
host | string | URL of your schema registry. | |
cacheSize | string | 50 | Number of schemas that can be cached locally by this interceptor so that it doesn't have to query the schema registry every time. |
| AWS Glue | Configuration for AWS Glue schema registries | ||
region | string | The AWS region for the schema registry, e.g. us-east-1 | |
registryName | string | The name of the schema registry in AWS (leave blank for the AWS default of default-registry) | |
basicCredentials | string | Access credentials for AWS (see below for structure) | |
| AWS Credentials | AWS credentials configuration | ||
accessKey | string | The access key for the connection to the schema registry. | |
secretKey | string | The secret key for the connection to the schema registry. | |
validateCredentials | bool | true | true / false flag to determine whether the credentials provided should be validated when set. |
accountId | string | The Id for the AWS account to use. |
If you don't supply a basicCredentials section for the AWS Glue schema registry, the client used to connect will attempt to find the connection information from the environment. The required credentials can be passed to Gateway in this way as part of core configuration.
Find out more in AWS documentation.
Example
{
"name": "mySqlTopicPlugin",
"pluginClass": "io.conduktor.gateway.interceptor.VirtualSqlTopicPlugin",
"priority": 100,
"config": {
"virtualTopic": "legal_user",
"statement": "SELECT * FROM users WHERE age > 18",
"schemaRegistryConfig": {
"host": "http://schema-registry:8081"
}
}
}
Schema Registry with secured template
{
"name": "mySqlTopicPlugin",
"pluginClass": "io.conduktor.gateway.interceptor.VirtualSqlTopicPlugin",
"priority": 100,
"config": {
"virtualTopic": "legal_user",
"statement": "SELECT * FROM users WHERE age > 18",
"schemaRegistryConfig": {
"host": "http://schema-registry:8081",
"additionalConfigs": {
"schema.registry.url": "${SR_URL}",
"basic.auth.credentials.source": "${SR_BASIC_AUTH_CRED_SRC}",
"basic.auth.user.info": "${SR_BASIC_AUTH_USER_INFO}"
}
}
}
}